Data Flows
Introduction
You often have a data flow from a source and through a series of
data processing application components. The flow could, for example, represent data from sensors to the cloud.
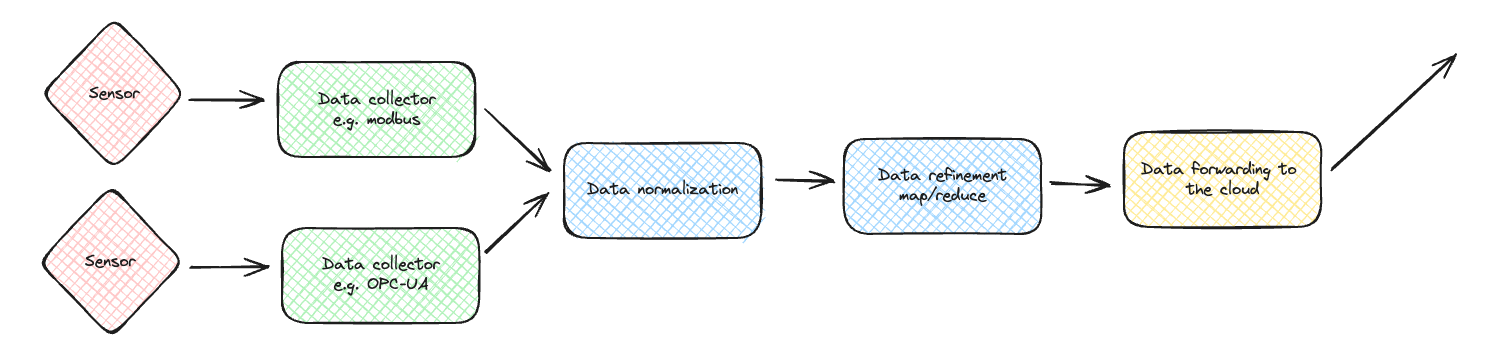 Typically, data is collected from one or more sensor types. In many cases, the
sensor data needs to be normalized before processing. Then, you could have a
data refinement step; in this step, the data is analyzed, transformed/mapped, and often reduced to save bandwidth to the cloud. Finally, the
data is forwarded to a central location, typically the cloud.
Typically, data is collected from one or more sensor types. In many cases, the
sensor data needs to be normalized before processing. Then, you could have a
data refinement step; in this step, the data is analyzed, transformed/mapped, and often reduced to save bandwidth to the cloud. Finally, the
data is forwarded to a central location, typically the cloud.
Chaining processing steps into a data flow
This howto explains how developers can stitch application components together to process a data flow using Avassa's pub/sub system. The
idea is that the application components utilize the Avassa built-in pub/sub bus
as indicated below.
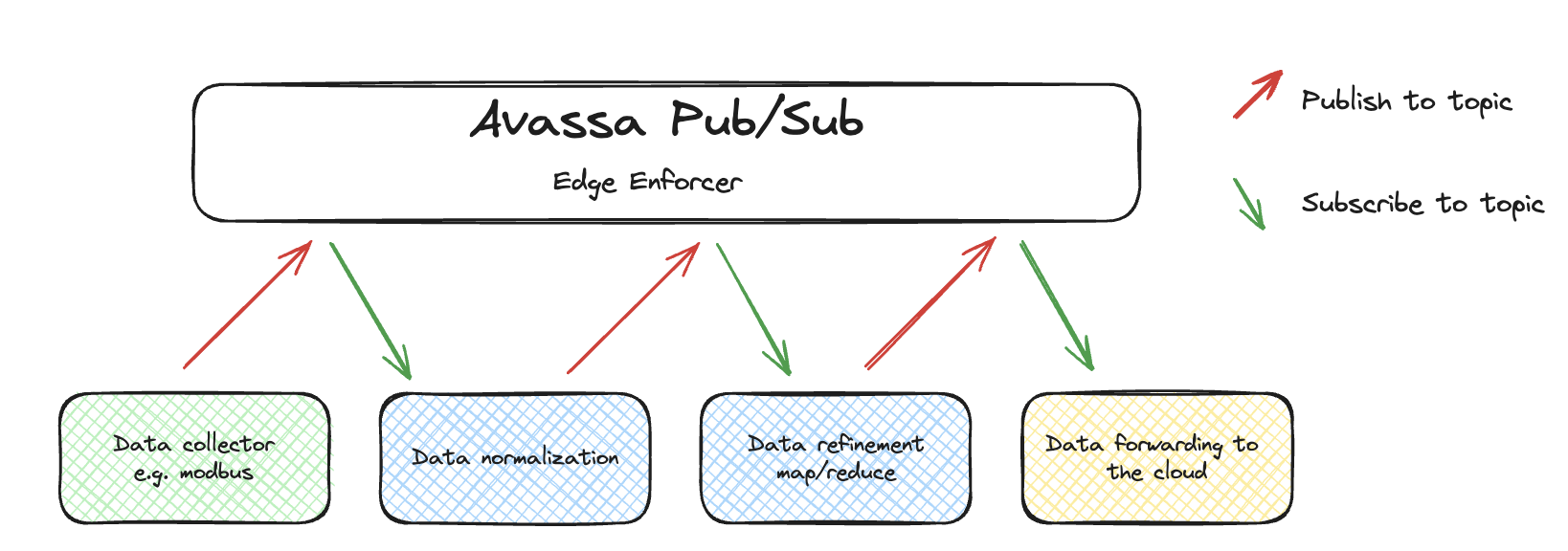
Each processing step in the data flow reads input data, processes the data, and publishes the processed data on a new topic. Then, the next step consumes data on the topic the previous step published data onto, forming a data flow/data pipeline.
Code
The demo application will subscribe to data on a topic called raw-sensor-data, do "something" with that
data and then pass it on on a topic named transformed-data.
#!/usr/bin/env python3
import asyncio
import avassa_client
import avassa_client.volga as volga
import sys
# Do something intelligent with the data
def process_data(data):
data['processed'] = True
return data
async def main(control_tower, username, password):
# In a real world app, use app_login
session = avassa_client.login(
host=control_tower,
username=username,
password=password,
)
# Used if the topic doesn't exist
create_opts = volga.CreateOptions.create(fmt='json')
# We will consume data from this topic
topic_in = volga.Topic.local('raw-sensor-data')
# We will product data on this topic
topic_out = volga.Topic.local('transformed-data')
async with volga.Consumer(session=session,
consumer_name='demo-consumer',
topic=topic_in,
mode='exclusive',
position=volga.Position.unread(),
on_no_exists=create_opts) as consumer:
# Tell the consumer we're ready for messages
await consumer.more(1)
async with volga.Producer(session=session,
producer_name='demo-producer',
topic=topic_out,
on_no_exists=create_opts) as producer:
while True:
# Get the next sensor reading
msg = await consumer.recv()
# transform/map/reduce the data
data_out = process_data(msg['payload'])
# Send it to the topic
await producer.produce(data_out)
# Let the system know we've handled the message
await consumer.ack(msg['seqno'])
if __name__ == "__main__":
control_tower=sys.argv[1]
username=sys.argv[2]
password=sys.argv[3]
asyncio.run(main(control_tower, username, password))
To test this out, we produce some JSON on a the raw-sensor-data topic using the CLI:
supctl do volga topics raw-sensor-data produce '{"temp": 10}'
And then we can consume, again using the CLI, on the transformed-data topic:
supctl do volga topics transformed-data consume --payload-only --follow
{
"temp": 10,
"processed": true
}
Summary
With a few lines of code you can easily subscribe, transform and publish data in a data flow.
The Python client used above can be found at PyPi.
There is also a Rust version at crates.io.